LLM Basics
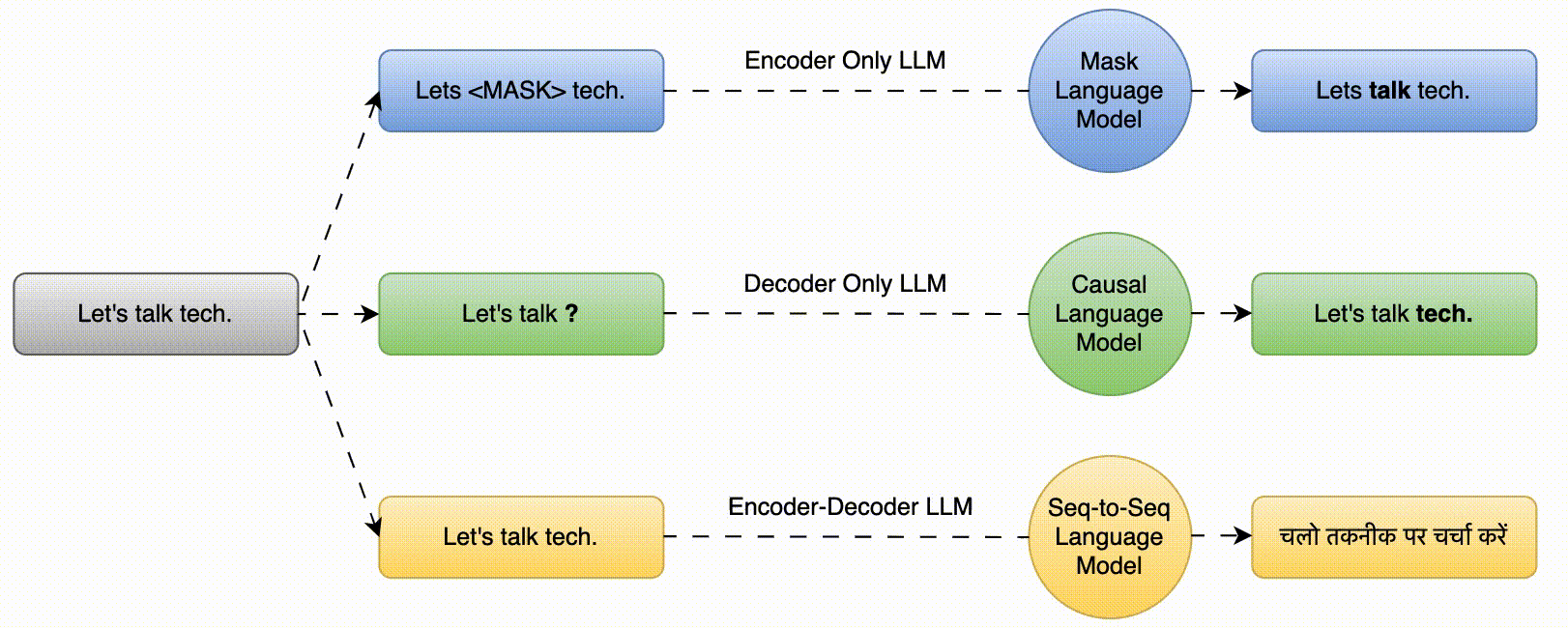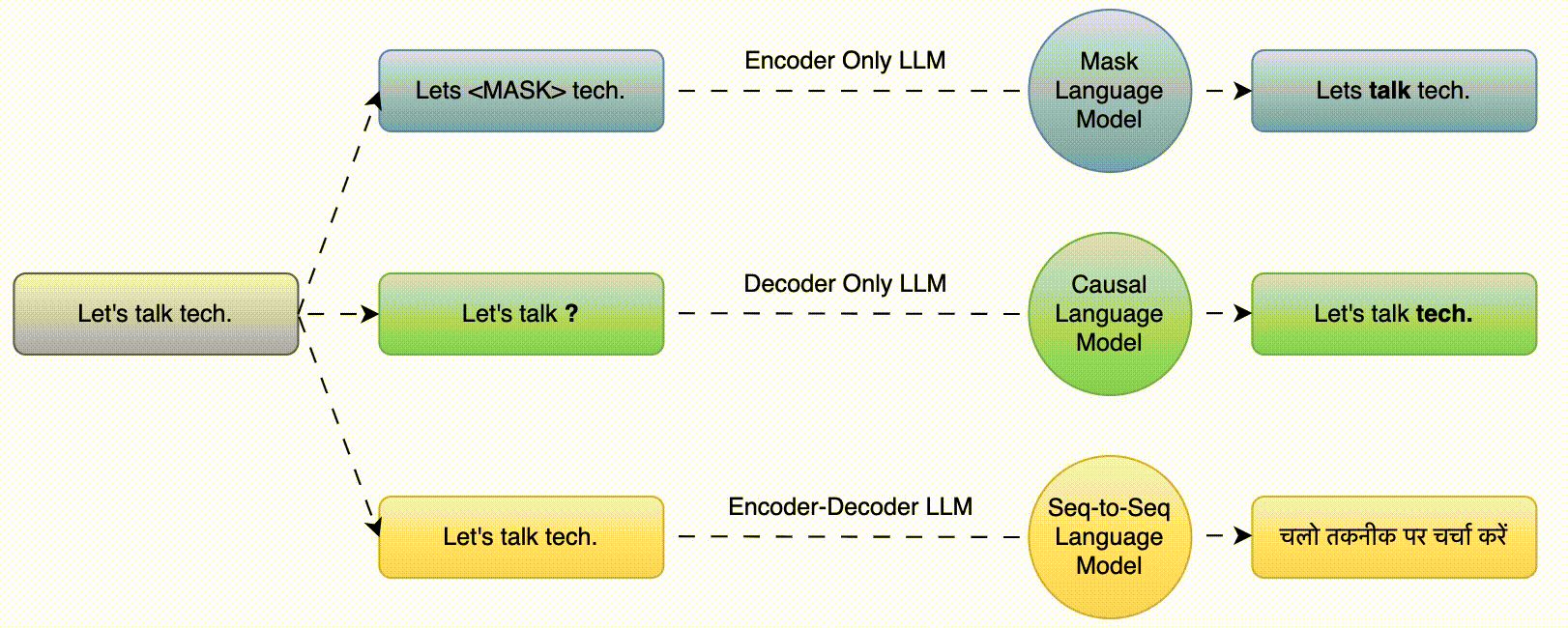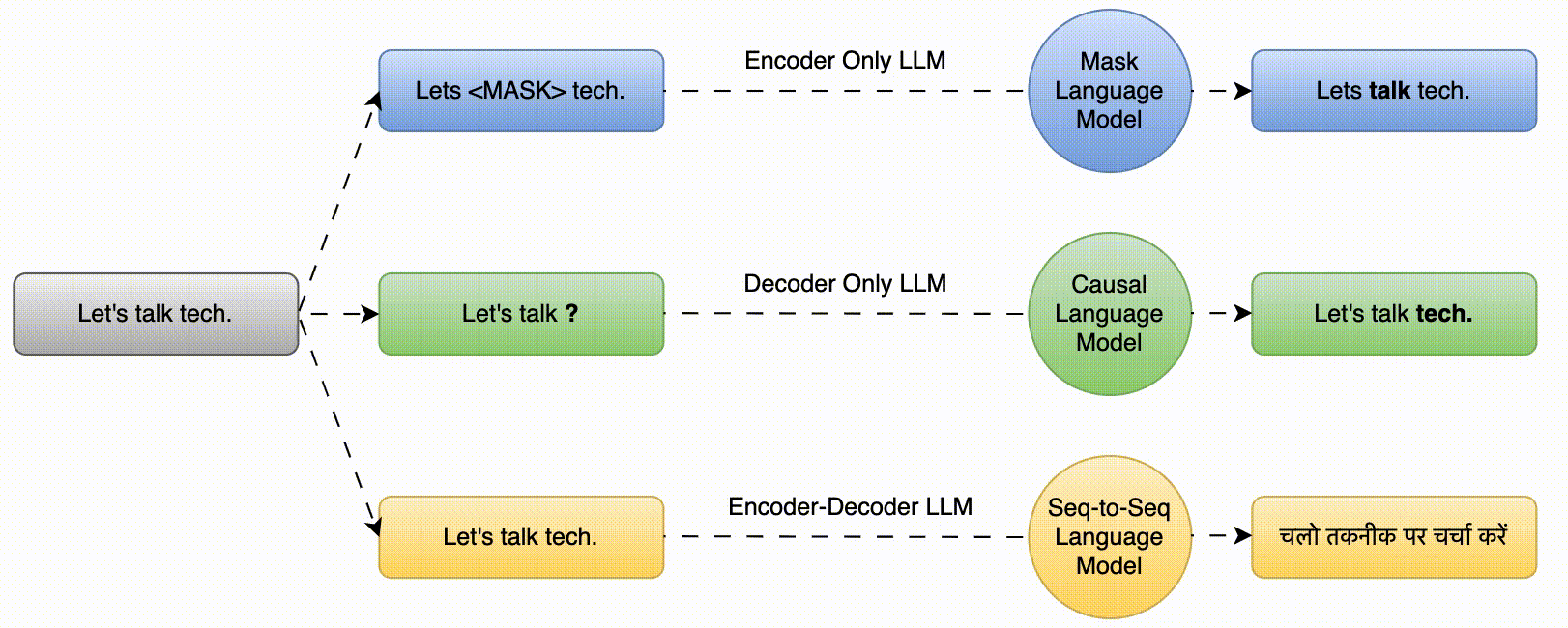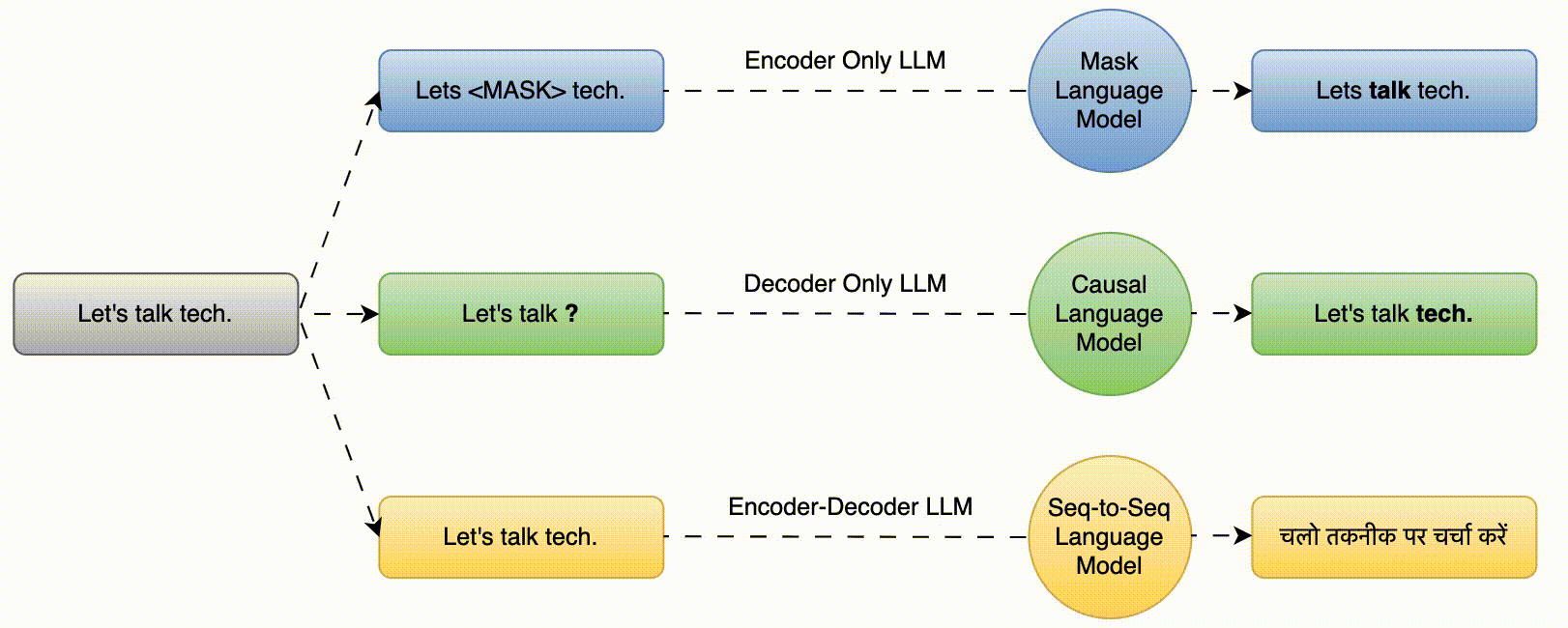
The key characteristic of Large Language Models (LLMs) is their ability to understand and generate human language. LLMs based on transformer architecture are mainly of three types i.e., Mask Language Model (predict the masked words based on the surrounding context), Causal Language Model (predict the next word in a sequence given the preceding words) and Seq-to-Seq Model (translation, summarization etc.)
In this post, we’ll delve deep into LLM architecture, pretraining, fine tuning, evaluation metrics, evaluation benchmarks. We’ll also explore optimization techniques at inference time and some of the LLM-powered applications.
We're going to dive pretty deep into the rabbit hole, and having a good understanding of machine learning and deep learning is a must for this blog. But if you think you're ready for it 😇, grab a cup of coffee and get ready to dive in deep, because this blog is on LLMs. My name is Rahul, and Welcome to TechTalk Verse! 🤟
An LLM training project’s life cycle consists mostly of three phases:
- Pretraining
- Instruction Fine Tuning
- Reinforcement Learning with Human Feedback (RLHF).
In this piece, I’ll only give a general overview of how an LLM is trained at various stages.
Transformers
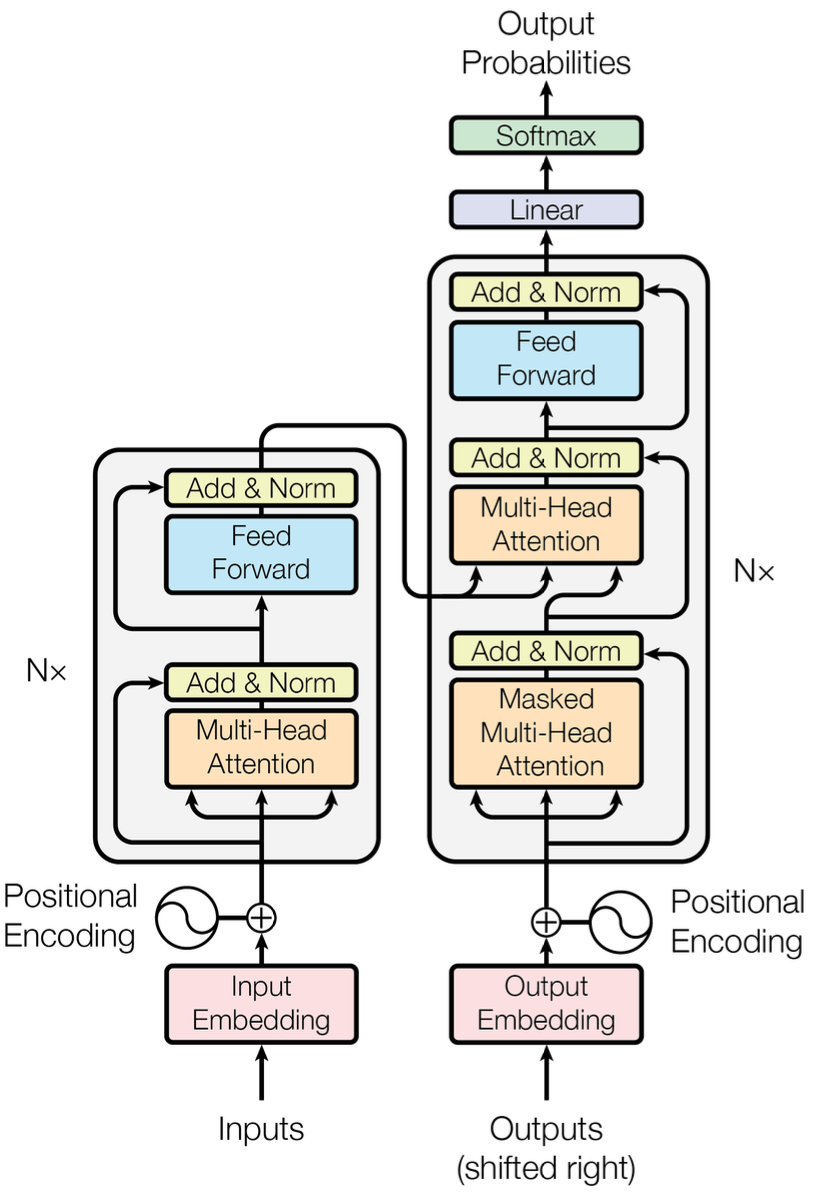
Above encoder-decoder is the model architechure for transformers. Without going into much deeper, I’ll just explain how an input sentence is propagated through different layers (tokenizer, positional encoder, masked multi-head attention, multi-head attention, feed-forward etc) in a transformer.
The very first step, like in most of the NLP models, is tokenization. Byte Pair Encoding (BPE) tokenization is used in transformers. So the input is a list of token IDs for the words of a sentence, which is fed into the transformer model. Now the token IDs are converted into embeddings after passing through the embedding layer. Next, there are positional embedding layers, which inject position information about the relative positions of tokens in the sequence. The positional encodings have the same dimension as the embeddings, so both can be summed.
Now, these embeddings are passed to the encoder, which consists of six identical layers. Each layer consists of multi-head attention layers and fully connected feed-forward layers. A residual (skip) connections is employed around each of two sub-layers of encoders followed by a normalizaion layer.
Attention layer outputs are weighted sum of values, where weights are calculated using queries and keys. The most commonly used attention functions are additive and dot-product attention. In the transformers, dot-product attention is used. Go through the-attention-mechanism-from-scratch for a good understanding and working of a attention layer.
Decoder too consists of six identical layers, and each layer has three sublayers, which are Masked Multi-Head Attention, Multi-Head Attention and fully connected feed-forward layers. The output token embeddings are passed into the decoder stacks, but these embeddings are offset by one position. So the masked multi-head attention layer and ofsetting the embeddings ensure that the predictions for position i can depend only on the known outputs at positions less than i.
Now, the masked multi-head attention layer output and the output from the encoder are fed to the third decoder sub-layer, i.e., the multi-head attention layer.
Encoder Models
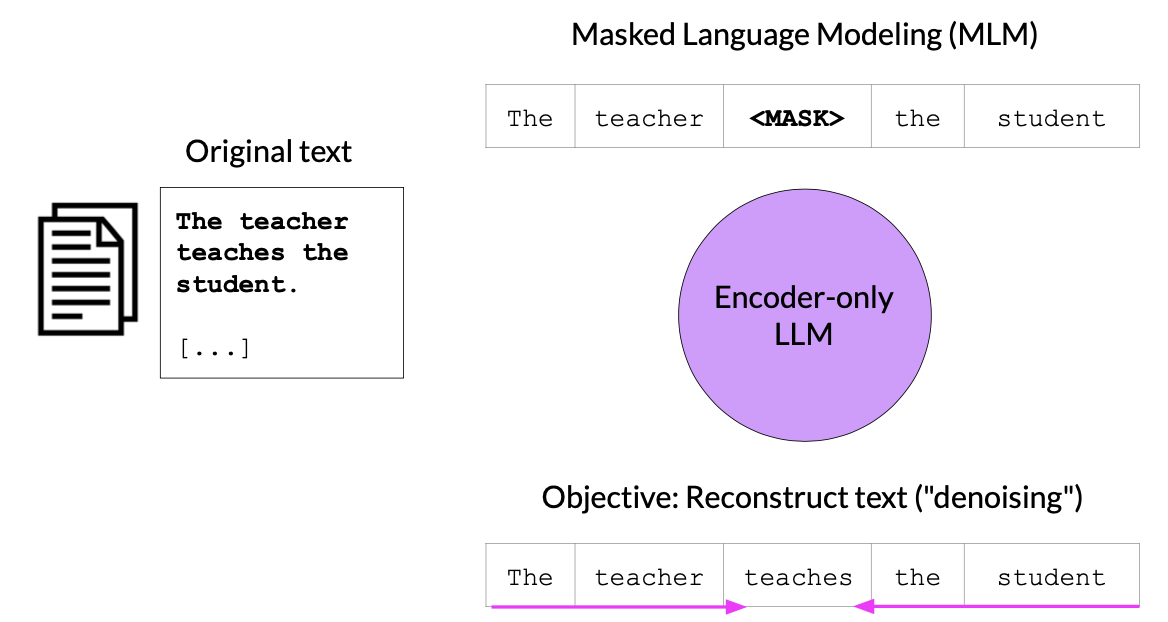
These are also called Autoencoding Models. These models uses Mask Language Modeling (MLM) for training.
- MLM is a self-supervised task commonly used in pretraining models like BERT.
- In MLM, a model is pretrained on a large corpus of text, and during this pretraining, some of the words in the input text are randomly masked.
- The model’s objective is to predict the masked words based on the surrounding context.
- This self-supervised pretraining helps the model learn rich representations of language that can be fine-tuned for downstream tasks.
Input –> The teacher <MASK> the student.
Output –> The teacher teaches the student.
Usecases : Sentiment Analysis, Named Entity Classification, etc.
Model Ex. : BERT, RoBERTa, etc
Decoder Models
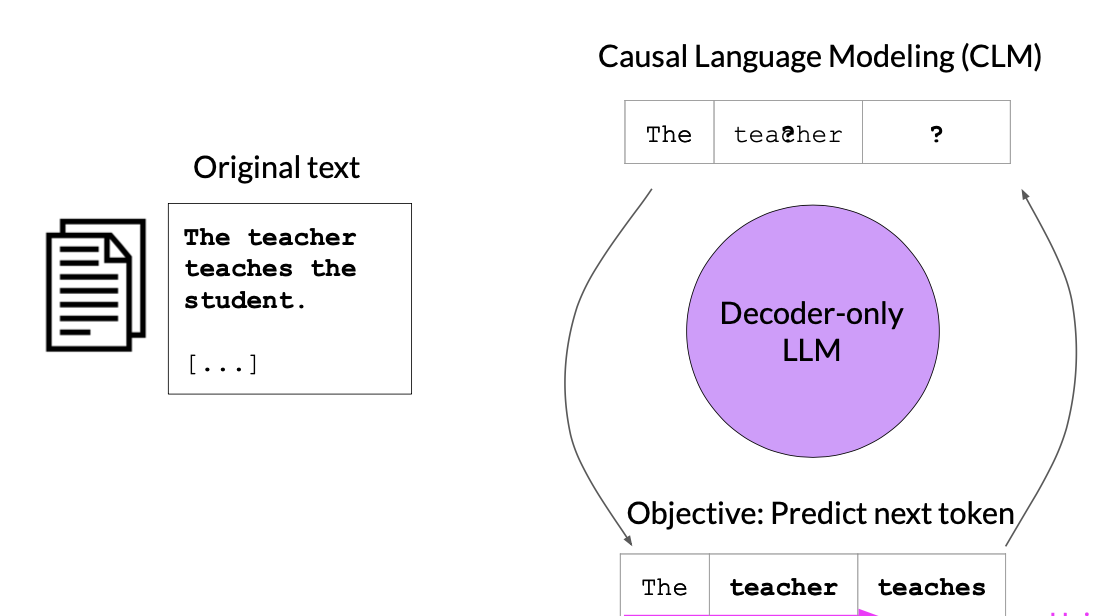
These are also called Autoregressive models. These models uses Causal Language Modeling (CLM) for training i.e., next word prediction.
- CLM is another self-supervised task used for pretraining models like GPT (Generative Pretrained Transformer).
- In CLM, a model is pretrained on a large text corpus and is trained to predict the next word in a sequence given the preceding words.
- It models the causal relationship between words, focusing on autoregressive generation.
- Similar to MLM, CLM aims to learn powerful language representations that can be fine-tuned for various NLP tasks.
Input –> The teacher ____
Output –> The teacher teaches
Usecases : Text Generation, etc
Model Ex : GPT, BLOOM, etc
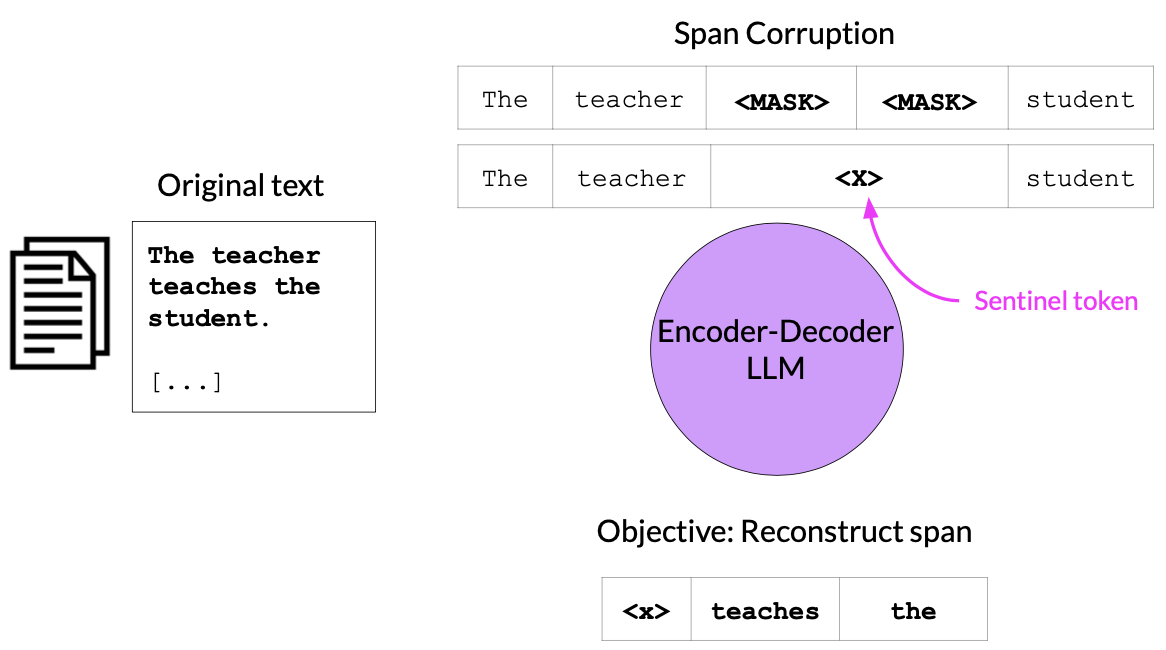
Encoder-Decoder Models
- These are sequence to sequence models.
- Seq2Seq models are typically used for supervised learning tasks.
- In Seq2Seq tasks, a model is trained on paired input-output sequences (e.g., translation pairs for machine translation).
- The model learns to generate an output sequence (e.g., a translation) given an input sequence.
- Usecases : Translation, Text Summarization, Question & Answering etc.
- Model Ex : T5, BART, etc.
Pretraining
During this phase, model is pretrained on a large amout of unstructured textual dataset in self-supervised manner. The main challenge in pretraining is computational cost.
GPU RAM required to store 1B parameter model
=> 1 parameter –> 4 bytes (32 bit float)
=> 1B parameter –> 4*10^9 bytes = 4GB
GPU RAM Required for 1B paramter model = 4GB@32 bit full precission
Let’s calculate memory required to train 1B parameter model:
Model Parameter --> 4 bytes per parameter
Gradients --> 4 bytes per parameter
ADAM Optimizer (2 states) --> 8 bytes per parameter
Activations and temp memory (variable size) --> 8 bytes per parameter (high-end estimate)
==> 4 bytes parameter + 20 extra bytes per paramterSo, memory need to train is ~20X memory needed to store the model.
Memory needed to store 1B parameter model = 4GB@32 bit full precission
Memory needed to train 1B parameter model = 80GB@32 bit full precission
Quantization
Memory usage can be reduced by reducing precision from 32 bit floating point number to 16 bit floating number or 8 bit integers. Following datatypes can be used to train a quantized models:
- FP32 –> 32 bit floating point
- FP16 –> 16 bit floating point
- BFLOAT16 –> 16 bit floating point half precision
- INT8 –> 8 bit integers
BFLOAT16 is truncated FP32. BFLOAT16 is used to pretrain most of the LLMs including FLAN T5. Given is below is the ram requirements to store 1B parameter model:
- Full Precision Model –> 4GB@32 bit full precission
- 16-bit quantized Model –> 2GB@16 bit half precission
- 8-bit quantized Model –> 1GB@8 bit precission
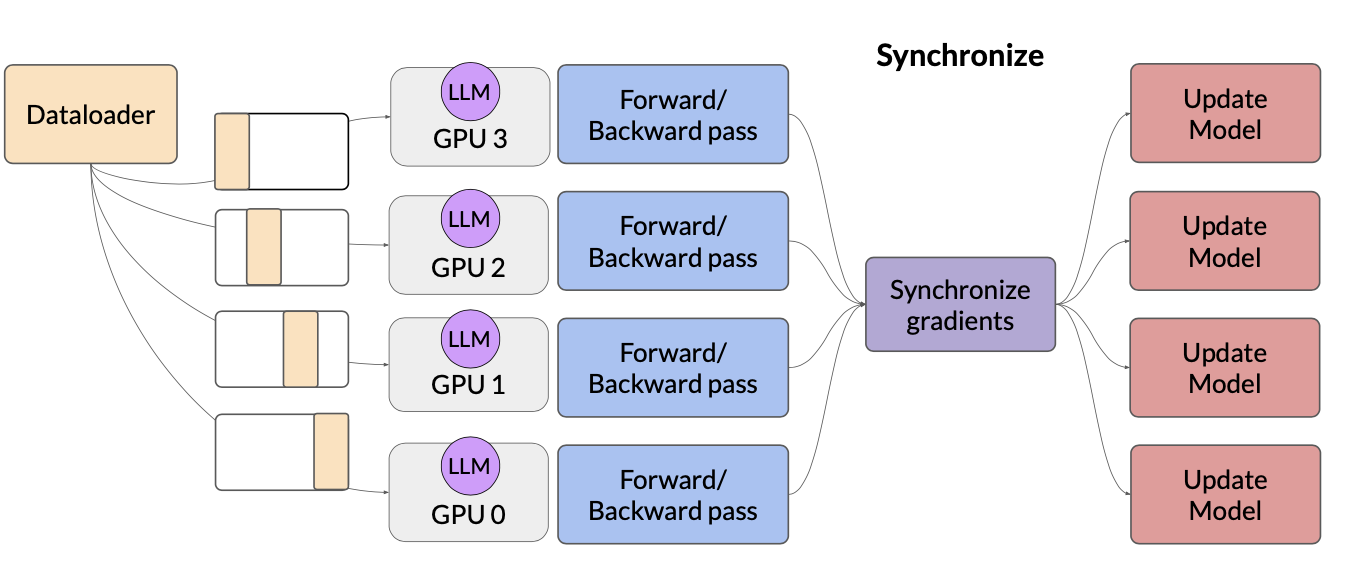
DDP
Distributed Data Parallel (DDP) requires model weights and all other additional parameters, gradients, optimizer states that are needed for training fit in a single GPU. If the model
is too big, model sharding should be used instead.
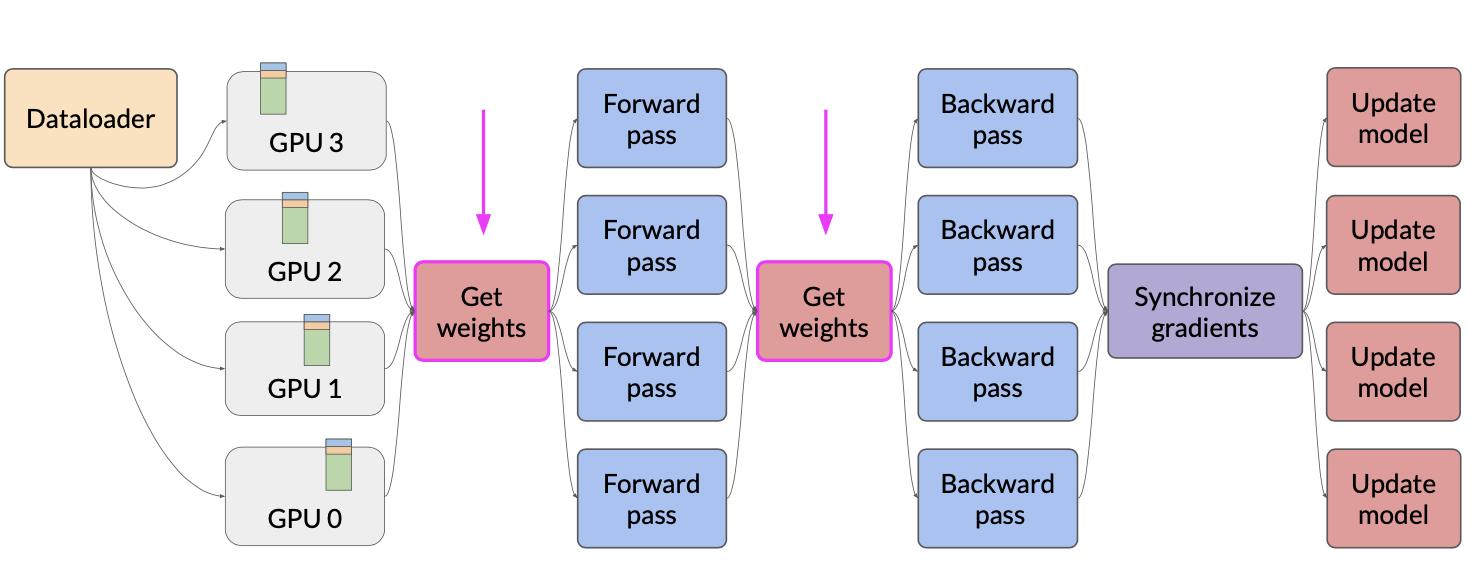
FSDP
Fully Sharded Data Parallel (FSDP) reduces memory by distributing (sharding) the model parameters, gradients and optimizer states across GPU’s.
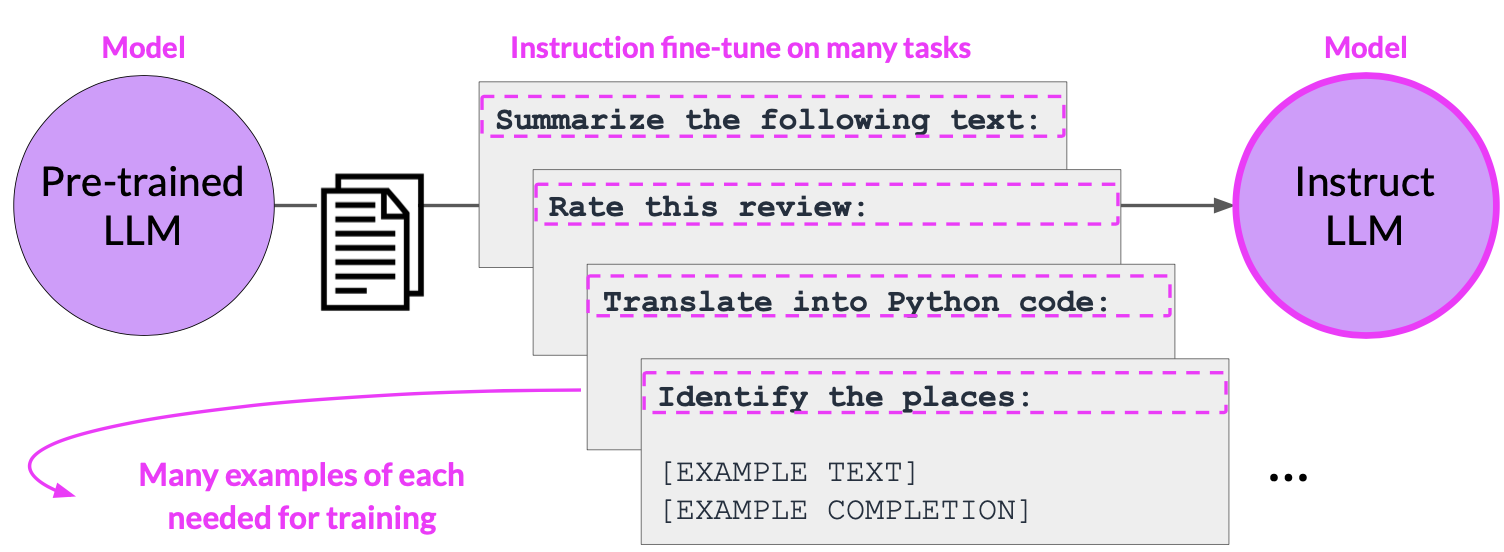
Fine-tuning
Fine-tuning in LLM mostly implies instruction fine tuning. As compared to traditional fine tuning, Instruction fine-tuning goes one step further by including high-level instructions or demonstrations to direct the model’s behaviour. Instruction fine-tuning uses a set of labeled examples in the form of {prompt, response} pairs to further train the pre-trained model in adequately predicting the response given the prompt. Fine tuning on a single task may lead to catastrophic forgetting. To avoid catastrophic forgetting :
- Fine tune on multiple tasks at the same time.
- Use Parameter Efficient Fine-tuning (PEFT)
PEFT
Parameter Efficient Fine-tuning (PEFT) updates only a small subset of parameters. This helps prevent catastrophic forgetting and also save computational cost as compared to full scale fine-tuing. These are some PEFT methods:
- Selective : select subset of initial LLM parameters to fine-tune.
- Reparameterization : Reparameterize model weights using a low rank representaion. Ex. LoRA
- Additive : Add trainable layers or parameters to model. Ex. Adapters, Soft prompts etc.
LoRA
Low Rank Adaptation (LoRA) is one of the PEFT methods where we reparameterize model weights using a low-rank representation. Given below are the main steps for fine-tuning with LoRA :
- Freeze most of the original LLM weights.
- Inject 2 rank decomposition matrices
- Train the weights of the smaller matrices
Steps to update model for inference :
- Matrix multiply the low rank matrices. These 2 low rank matrices (a,b) is formed such that shape(bXa) = shape (BXA) where B,A are original weight matrices.
- Add these to original weights => bXa + BXA
LoRA concrete example using base Transformer as reference
Use the base Transformer model presented by Vaswani et al. 2017:
- Transformer weights have dimensions d x k = 512 x 64
- So 512 x 64 = 32,768 trainable parameters
In LoRA with rank r = 8:
- A has dimensions r x k = 8 x 64 = 512 parameters
- B has dimension d x r = 512 x 8 = 4,096 trainable parameters
86% reduction in parameters to train!
Prompt tuning
Prompt tuning adds trainable soft prompt to inputs. With promt tuning, we add additional trainable tokens to our prompt and leave it up to supervised learning process to determine their optimal values.
RLHF
Reinforcement Learning from Human Feedback (RLHF) is required to tranform the instruct Fine-tuned LLM into human aligned LLM. RL model is formulated in case of LLM is as follows :
- Agent –> Instruct Fine-tuned LLM
- Action –> Next token generation
- Action Space –> Vocabulary of all tokens.
Goal of instruct fine-tuning:
- Better understanding of prompts
- Better task completion
- More natural sounding language
Goal of RLHF:
- Maximize helpfulness, relevance
- Minimize harm
- Avoid dangerous topics
Optimization Techniques.
Quantization
Post training, quantization transforms a model’s weight to a lower precision representation like 16 bit float, or 8 it integer.
Distillation
Distillation uses a larger model, the teacher model to train a smaller model, the student model. The smaller model is then used for inference to lower your storage and compute cost.
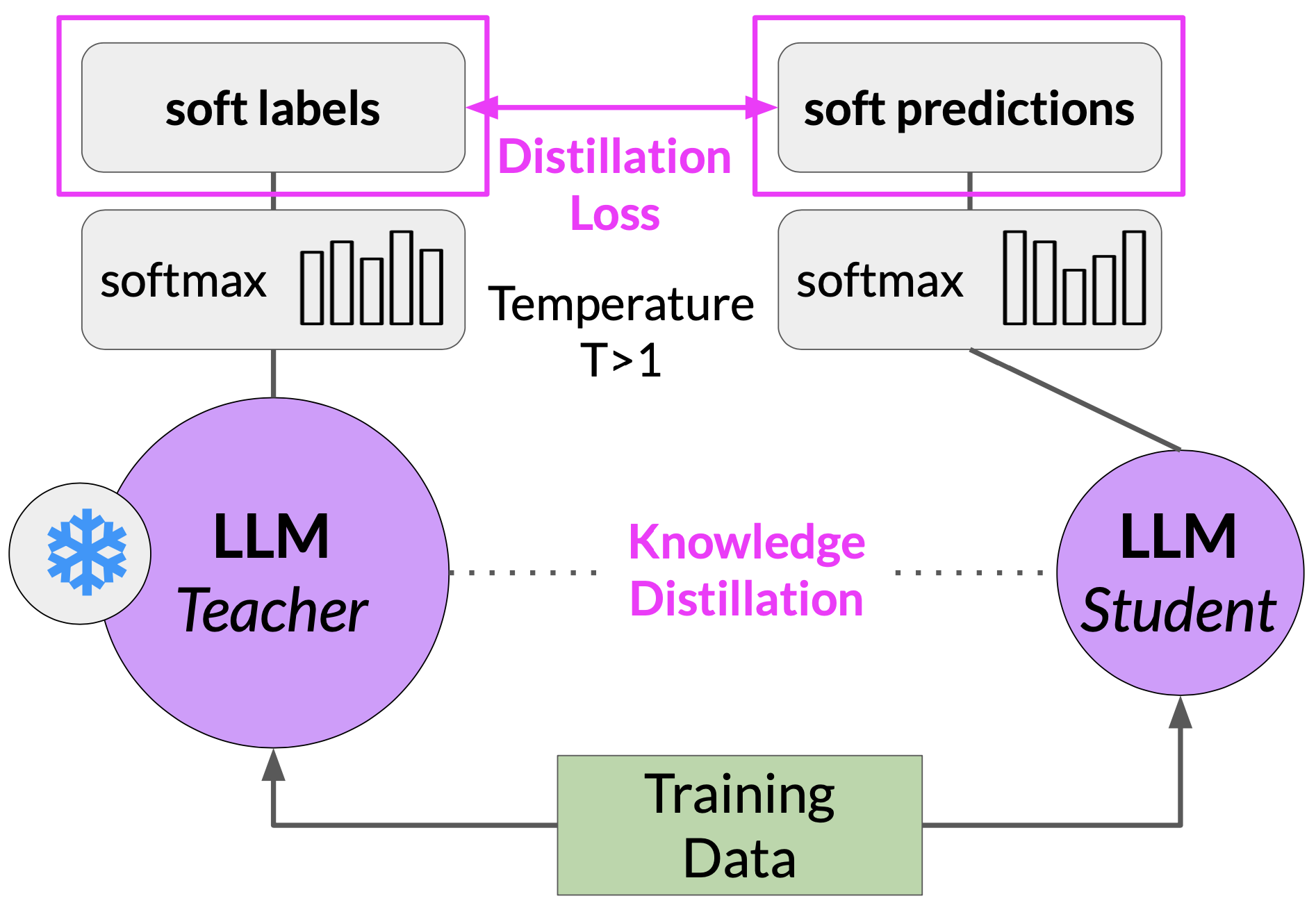
Distillation
SO, when temperature > 1 then, probability distribution becomes broader.
T > 1 => Teacher’s output –> soft labels and Student’s output –> soft predictions
T = 1 => Teacher’s output –> hard labels and Student’s output –> hard predictions
Distillation is not as effective for generative decoder models. Its effective for encoder only models, such as BERT, which have a lot of representation redundancy.
Pruning
Model Pruning removes redundant model parameters that contribute little to the model’s preformance. It removes model weights with values close or equal to zero.
LLM-powered applications
Langchain
The LangChain framework is built around LLMs and allows the chaining of various components to create more advanced applications for LLMs. It supports use cases like chatbots, Generative Question-Answering (GQA), and summarization.
RAG
Retrieval Augmented Generation (RAG) : The retriever component retrieves relevant information from an external corpus or knowledge base, which is then used by the model to generate more informed and contextually relevant responses. This incorporation of external knowledge enhances the quality and relevance of the generated content. Retrieving data from external sources enables the model to incorporate information it did not see during training when generating text.
PAL
Program-aided Language (PAL) : It offloads these tasks to a runtime symbolic interpreter such as a python function, which reduces the workload for the LLM and improves accuracy as symbolic interpreters tend to be more precise with computational tasks.
ReACT
The ReAct framework aims to enhance both language understanding and decision-making capabilities in LLMs by combining reasoning and acting components.
Evaluation Metrics.
ROUGE
It is Recall-Oriented Understudy for Gisting Evaluation. This metric measures the quality of text summarization.
ROUGE-1 Recall = \( \frac{Unigrams \ matches}{Unigrams \ in \ reference} \)
ROUGE-1 Precision = \( \frac{Unigrams \ matches}{Unigrams \ in \ output} \)
ROUGE-2 Recall = \( \frac{Bigrams \ matches}{Bigrams \ in \ reference} \)
ROUGE-2 Precision = \( \frac{Bigrams \ matches}{Bigrams \ in \ output} \)
LCS-L Recall = \( \frac{LCS(gen, ref)}{Unigrams \ in \ ref} \)
LCS-L Precision = \( \frac{LCS(gen, ref)}{Unigrams \ in \ output} \)
NOTE : LCS stands for Longest Common Subsequence, gen is generated output and ref is reference.
BLEU
It is Bilingual Evaluation Understudy. This metric measures quality of text translation.
BLUE Metric = Avg(Precision across range of n-gram sizes)
Perplexity
Perplexity is a metric for autoregressive or causal language models. Its not well defined for masked language models like BERT. Perplexity is defined as the exponentiated average negative log-likelihood of a sequence. If we have a tokenized sequence \( X = (x_0, x_1, . . . , x_t) \), then perplexity of X is,
\( PPL(X) = \exp[-\frac{1}{t}\sum\limits_{i}^{t}\log p_{\theta}(x_i|x_{<i}) ] \)
This is also equivalent to the exponentiation of the cross-entropy between the data and model predictions.
Evaluation Benchmarks
GLUE
GLUE is Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Tasks in GLUE includes single sentence tasks (sentiment, acceptability), similarity, parapharase task, inference tasks (NLI, QA) etc.
SuperGLUE
SuperGLUE is a stickier benchmark for General-Purpose Language Understanding Systems. Tasks in SuperGLUE includes QA, NLI, WSD, etc.
HELM
It stands for Holistic Evaluation of Language Models. It test the model with datasets like OpenBookQA, TruthfulQA, IMDB, RAFT etc with metrics like Accuracy , Calibration, Robustness, Fairness, Bias, Toxicity, Efficiency, etc.
MMLU
It stands for Massive Multitask Language Understanding. As the name suggests, these benchmarks are for massive models.