LLM Verse
Encoder Models
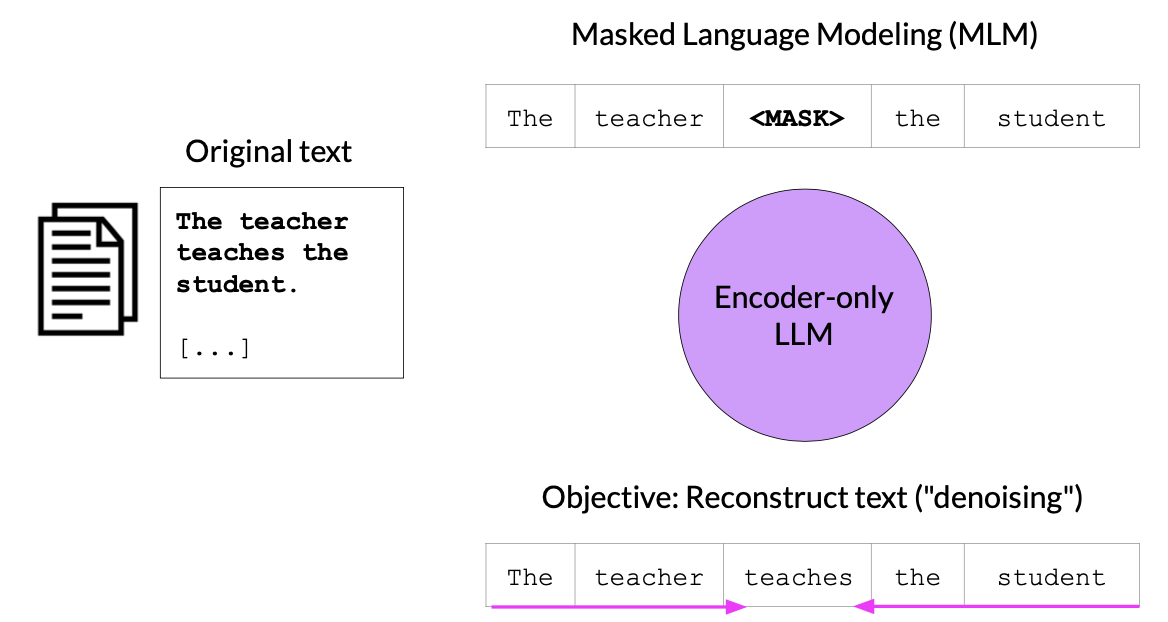
These are also called Autoencoding Models. These models uses Mask Language Modeling (MLM) for training.
Input –> The teacher <MASK> the student.
Output –> The teacher teaches the student.
Usecases : Sentiment Analysis, Named Entity Classification, etc.
Model Ex. : BERT, RoBERTa, etc
BERT
Overview
- Developed by Google in 2018.
- Stands for Bidirectional Encoder Representations from Transformers.
Dataset Details
- Trained using 16GB of data.
- Trained with 3.3B words.
- Trained on corpora BookCorpus and English Wikipedia.
Model Details
- 110M parameters with 12 encoders (BERT-base).
- 340M parameters with 24 encoders(BERT-large).
- WordPiece tokenizer.
- 512 token context length
RoBERTa
Overview
- Developed by Meta.
- Stands for Robustly Optimized BERT.
Dataset Details
- Trained using 160GB of data.
Model Details
- 123M parameters with 12 encoders (RoBERTa-base).
- 354M parameters with 24 encoders(RoBERTa-large).
Roberta is trained with:
- Full Sentences without NSP loss.
- Dynamic Masking
- Large Mini-batches
- Larger byte-level BPE
DeBERTa —> to be
Decoder Models
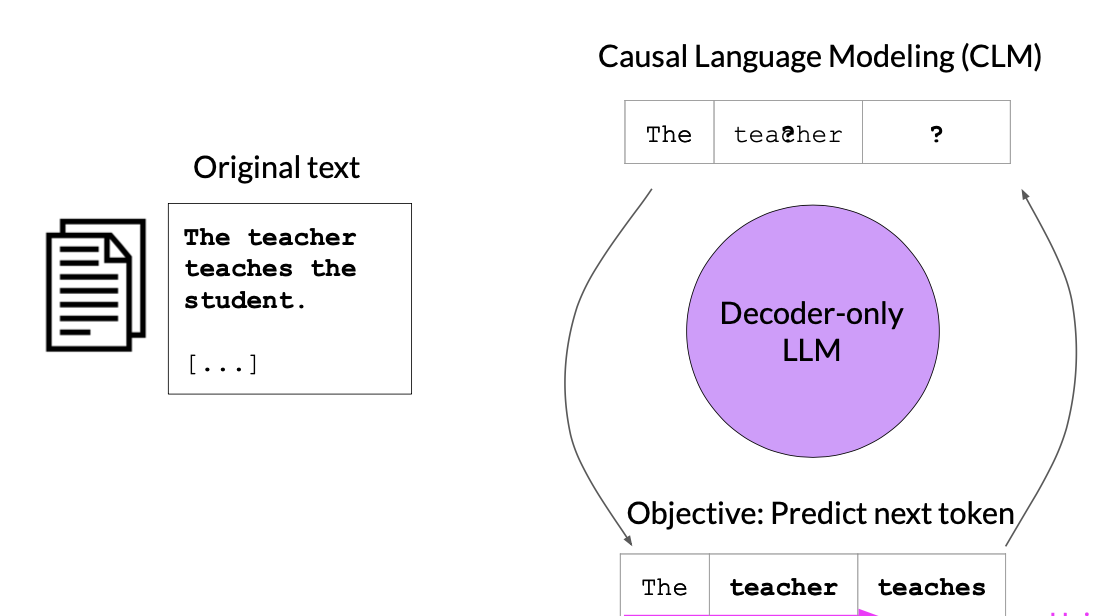
These are also called Autoregressive models. These models uses Causal Language Modeling (CLM) for training i.e., next word prediction.
Input –> The teacher ____
Output –> The teacher teaches
Usecases : Text Generation, etc
Model Ex : GPT, BLOOM, etc
GPT 1
Overview
- Stands for Generative Pre-trained Transformer
- Developed by OpenAI in 2018.
Dataset Details
- Trained on ~600B Tokens.
- Trained with Book Corpus dataset and common crawl.
Model Details
- 117M parameters.
- BPE tokenizer.
- 0.5K token context length
GPT 2
Overview
- Developed by OpenAI in 2019.
Dataset Details
- Trained on ~450B Tokens.
- Trained with Book Corpus(7K) and 8M webpages.
Model Details
- 1.5B parameters.
- BPE tokenizer.
- 1K token context length
GPT 3
Overview
- Developed by OpenAI in 2020.
Dataset Details
- Trained on common crawl, wikipedia , books and codes.
Model Details
- 175B parameters.
- BPE tokenizer.
- 2K token context length
GPT 3.5
Overview
- Developed by OpenAI in Jan, 2022.
- ChatGPT is powered by GPT-4 model
- Upgraded version of GPT 3 with fewer parameters and RLHF fine tuning.
Dataset Details
- Trained on common crawl, wikipedia etc
Model Details
- 1.3B, 6B and 175B parameters and 12 layers.
- 4K token context length
GPT 4
Overview
- Developed by OpenAI in March, 2023.
- It is multimodal model (accepts both images and text)
- Bing Chat is powered by GPT-4 model
Dataset Details
- Trained on ~13T Tokens.
- Common Crawl and Refined Web Dataset used.
Model Details
- 1.8T parameters and 120 layers.
- 8K and 32K token context length
LLaMA 1
Overview
- Developed by Meta in Feb, 2023.
- Stands for Large Language Model Meta AI.
Dataset Details
- LLaMA 7B is trained on 1T tokens.
- LLaMA 65B and 33B is trained on 1.4T tokens.
Model Details
- 7B, 13B, 33B, and 65B parameters
- BPE tokenizer.
- 2K token context length.
LLaMA 2
Overview
- Developed by Meta in July, 2023.
Dataset Details
- Pretrained on 2T tokens.
Model Details
- 7B/13B/70B parameters
- 4K token context length
Claude V1
Overview
- Developed by American AI startup Anthropic.
Dataset Details
- Pretrained on text dataset.
Model Details
- 93B parameters
- 100K context length.
Claude V2
Overview
- Developed by American AI startup Anthropic.
Dataset Details
- Pretrained on text and code dataset.
Model Details
- 137B parameters
- 100K context length.
Falcon
Overview
- Developed by the UAE’s Technology Innovation Institute (TII).
Dataset Details
- Pretrained on 1.5T tokens (7B parameter model)
- Pretrained on 1T tokens (40B parameter model)
- Refined Web Dataset used for pretraining.
Model Details
- 7B and 40B parameters
- 2K context length
PaLM
Overview
- Stands for Pathways Language Model.
- Developed by Google in April, 2022.
- BARD is powered by PaLM model
Dataset Details
- Pretrained on 780B Tokens.
Model Details
- 540B parameters
- 8K token context length
MPT
Overview
- Developed by MosaicML on May, 2023.
Dataset Details
- Pretrained on 1T tokens.
Model Details
- 7B and 30B parameters.
- 8K context length.
Vicuna
Overview
- Developed by LMSYS.
- It is fined-tuned LLaMA using Supervised instruction on sharegpt.com training data.
Model Details
- 33B parameters
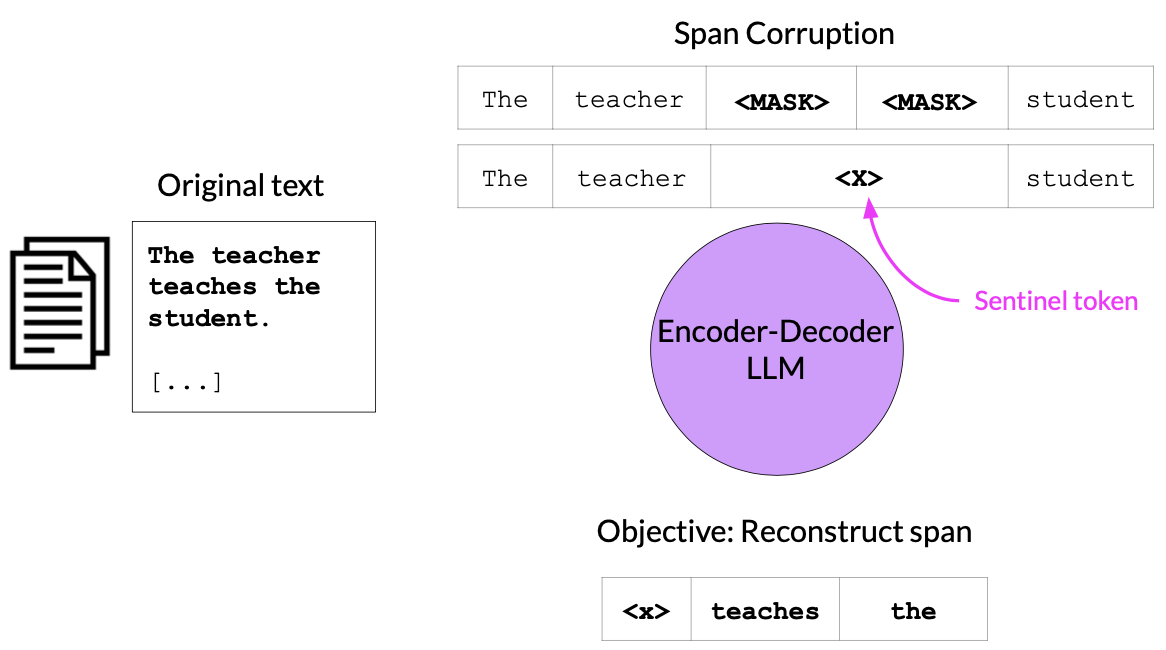
Encoder-Decoder Models
These are sequence to sequence models.
Usecases : Translation, Text Summarization, Question & Answering etc.
Model Ex : T5, BART, etc.
T5
Overview
- Stands for Text-to-Text Transfer Transformer.
- Flan T5 is a fine-tuned version of T5.
Dataset Details
- Trained on ~600B Tokens.
- C4 dataset used for training
Model Details
- 60M/220M/738M/3B parameters for small/Base/Large/XL models.