Large Action Models

We're going to dive pretty deep into the rabbit hole, and having a good understanding of Large Language Models (LLMs) is a must for this blog. But if you think you're ready for it 😇, grab a cup of coffee and get ready to dive in deep, because this blog is on Large Action Models (LAMs). My name is Rahul, and Welcome to TechTalk Verse! 🤟
Evolution
Earlier automation systems had random-based automation which used a random sequence of actions within the GUI without relying on specific algorithms or structured models using monkey tests. Then it slowly shifted to rule-based and script-based where it relied on predefined rules or detailed scripts to manage GUI interactions. Then there was a shift towards AI for automation. Machine learning and deep learning models were used as components for decision-making at intermediate steps for computer vision and natural language processing tasks. The introduction of LLMs, particularly multimodal models like GPT-4o (2023), has radically transformed GUI automation by allowing intuitive interactions through natural language. Unlike previous approaches that required the integration of separate modules, LLMs provide an end-to-end solution for GUI automation, offering advanced capabilities in natural language understanding, visual recognition, and reasoning.
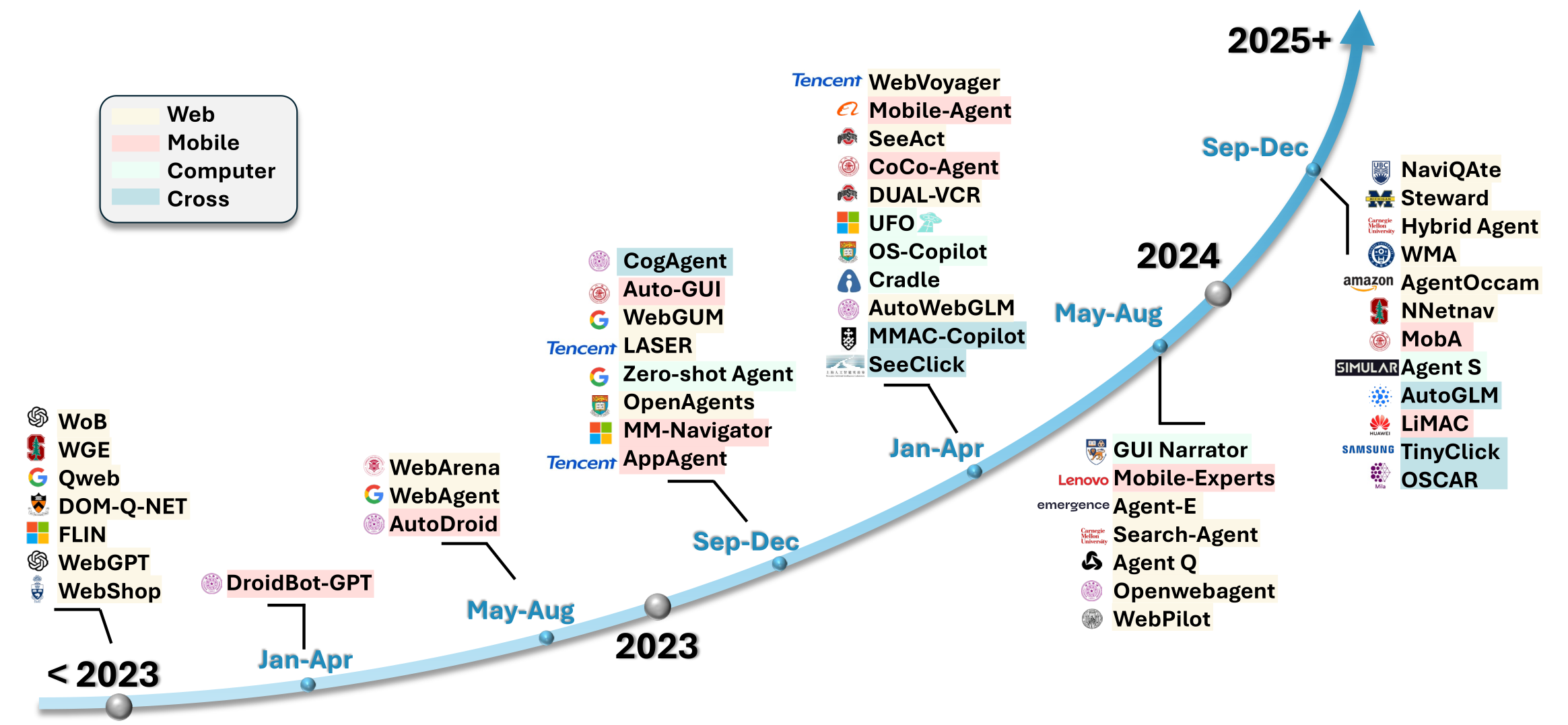
An overview of GUI agents evolution over years
LAMs
Large Action Models (LAMs) are the brain of these GUI agents. LAMs are the foundation models fine-tuned with contextual and GUI-specific datasets. GPT-4V, GPT-4o, Gemini and Claude 3.5 Sonnet are commonly used closed-source foundational LLM models. Apart from these are a lot of good open-source multi-modal foundational LLMs as well like the LLaVA model integrates the CLIP vision model encoder with the Vicuna language model decoder. InternVL-2 combines a Vision Transformer with a Large Language Model to handle text, images, video, and medical data inputs. Phi-3.5-Vision achieves competitive performance in multimodal reasoning within a compact model size. Some of the other open-source multi-modal LLMs are :
- Qwen-VL : 9.6B (Text and image modality)
- Qwen2-VL : 2B/7B/72B (Text, image and video)
- InternVL-2 : 1B/2B/4B/8B/26B/40B (Text, image, video, and medical data)
- CogVLM : 17B (Text and image modality)
- Ferret : 7B/13B (Text and image modality)
- LLaVA : 7B/13B (Text and image modality)
- BLIP-2 : 3.4B/12.1B (Text and image modality)
- Phi-3.5 : 4.2B (Text and image modality)
Now, below are LAMs fine-tuned from these foundational models
- WebGUM integrates HTML understanding with visual perception through temporal and local tokens. It leverages Flan-T5 for instruction fine-tuning and ViT for visual inputs, enabling it to process both textual and visual information efficiently.
- Agent Q (fined-tuned from Llama-3-70B) employs Monte Carlo Tree Search (MCTS) combined with self-critique mechanisms and Direct Preference Optimization (DPO) to improve success rates in complex tasks such as product search and reservation booking.
- OpenWebVoyager combines imitation learning with an iterative exploration-feedback optimization cycle.
- Octopus : Leveraging the MPT-7B and CLIP ViT-L/14, Octopus integrates egocentric and bird’s-eye views for visual comprehension, generating executable action code.
- CogAgent (finetuned from CogVLM) stands out as an advanced visual language model specializing in GUI understanding and navigation across PC, web, and Android platforms.
Architecture
Upon receiving a user request, the agent follows a systematic workflow that includes environment perception, prompt engineering, model inference, action execution, and continuous memory utilization until the task is fully completed.
it consists of the following components:
- Operating Environment: The operating environment can be platforms like mobile devices, web browsers or desktop OS like Windows, Linux etc.
- Prompt Engineering: This prompt incorporates user instructions, processed visual data (e.g., screenshots), UI element layouts, properties, and any additional context relevant to the task.
- Model Inference : LLM/LAM is the agent’s inference core. Model may be a general-purpose LLM or a specialized model fine-tuned with GUI-specific data.
- Action Execution : Based on the model’s inference results, the agent identifies specific actions (such as mouse clicks, keyboard inputs, touchscreen gestures, or API calls) required for task execution
- Memory : For multi-step tasks, the agent maintains an internal memory to track prior actions, task progress, and environment states
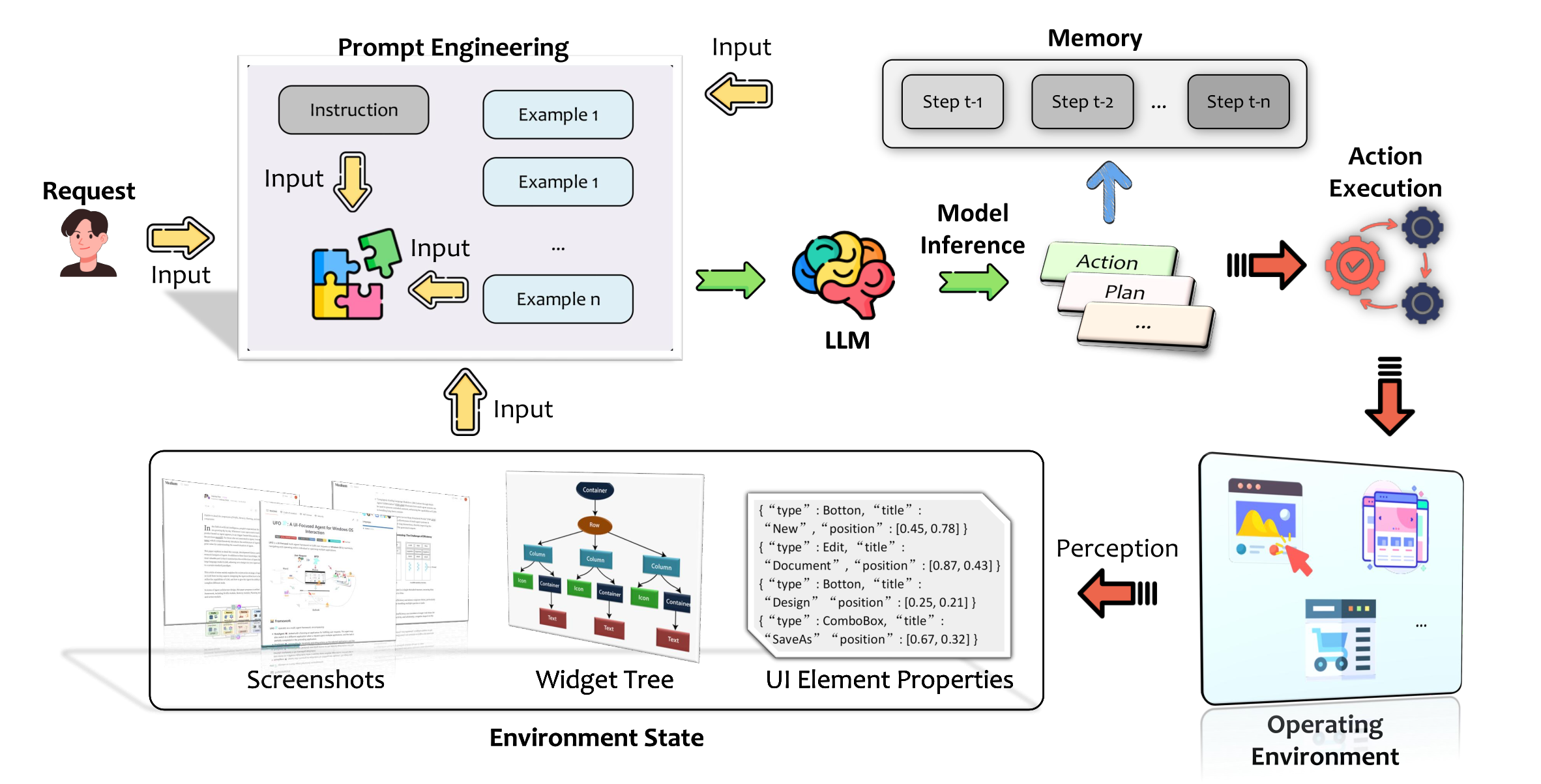
An overview of the architecture and workflow of a basic LLM-powered GUI agent
Frameworks
There are too many GUI agentic frameworks that are open source right now on the web. They are mostly categorized into web agents, mobile agents, computer agents and cross-platform agents. There are too many of them and here I’ll list out few of them. A lot more is listed in the LLM-brained GUI agents survey paper (in the reference).
- Web : SeeAct, WebVoyager, WebDreamer, SeachAgent, etc.
- Mobile : DroidBot-GPT, CoCo-Agent, MobileGPT, AppAgent, etc.
- Computer : ScreenAgent, UFO, UFO, Cradle, etc.
- Cross-platform : AGUVIS, Ponder & Press, AgentStore, etc.
The brains in these agents are LLMs like GPT-4, Llama-3, Claude or some specialized model fined-tuned with GUI-specific datasets specific to the platform. These agents take HTML/DOM structures with screenshots as input to LLM and perform standard GUI actions, bash and python commands and API calls.
Datasets
Data that is used for training a GUI agent requires substantial time and effort. This can be specific to mobile agents, web agents, computer agents and cross-platform agents. In most cases, data consists of the following parts :
- User Instructions: These provide the task’s overarching goal, purpose, and specific details, typically in natural language, offering a clear target for the agent to accomplish, e.g., “change the font size of all text to 12”.
- Environment Perception: This typically includes GUI screenshots, often with various visual augmentations, as well as optional supplementary data like widget trees and UI element properties to enrich the context.
- Task Trajectory: This contains the critical action sequence required to accomplish the task, along with supplementary information, such as the agent’s plan. A trajectory usually involves multiple steps and actions to navigate through the task.
While user instructions and environmental perception serve as the model’s input, the expected model output is the task trajectory.
Some of the datasets are :
Mind2Web is a crowdsourced web data consisting of 2350 tasks from 137 sites with content like task descriptions, action sequences, and web page snapshots.
GUI Odyssey is human and GPT-4 generated android data consisting of 7735 episodes across 201 apps with content like Textual
tasks, plans, action sequences and GUI screenshots.
LAM is Windows OS data collected from application documentation, WikiHow articles and Bing search queries via GPT-4. It consists of 76672 task-plan pairs, and 2192 task-action trajectories with content like Task descriptions in natural language, step-by-step plans, action sequences, and GUI screenshots.
Evaluation
Data that is used for training a GUI agent requires substantial time and effort. This can be specific to mobile agents, web agents, computer agents and cross-platform agents. In most cases, the following metrics are measured.
- Step Success Rate: Completing a task may require multiple steps. This metric measures the ratio of the number of steps that are successful over the total steps within a task.
- Step Success Rate: Completing a task may require multiple steps. This metric measures the ratio of the number of steps that are successful over the total steps within a task.
- Task Success Rate: Task success rate measures the successful task completion over all tasks set in the benchmark.
- Efficiency Score: Efficiency score evaluates how effectively the agent completes tasks while considering resource consumption, execution time, or total steps the agent might take.
- Completion under Policy: This metric measures the rate at which tasks are completed successfully while adhering to policy constraints.
- Risk Ratio: Similar to the previous metric, the risk ratio evaluates the potential risk associated with the agent’s actions during task execution.